In the dynamic world of data management, distinguishing between data pipelines and ETL (Extract, Transform, Load) pipelines is vital for businesses aiming to optimize their data strategies. The increasing influx of data, coupled with advancements in technologies like machine learning (ML), has revolutionized traditional ETL pipelines into more versatile frameworks. Let’s explore the intricate differences, applications, and considerations for choosing between ETL and data pipelines.
1. Overview of Data Pipelines and ETL Pipelines
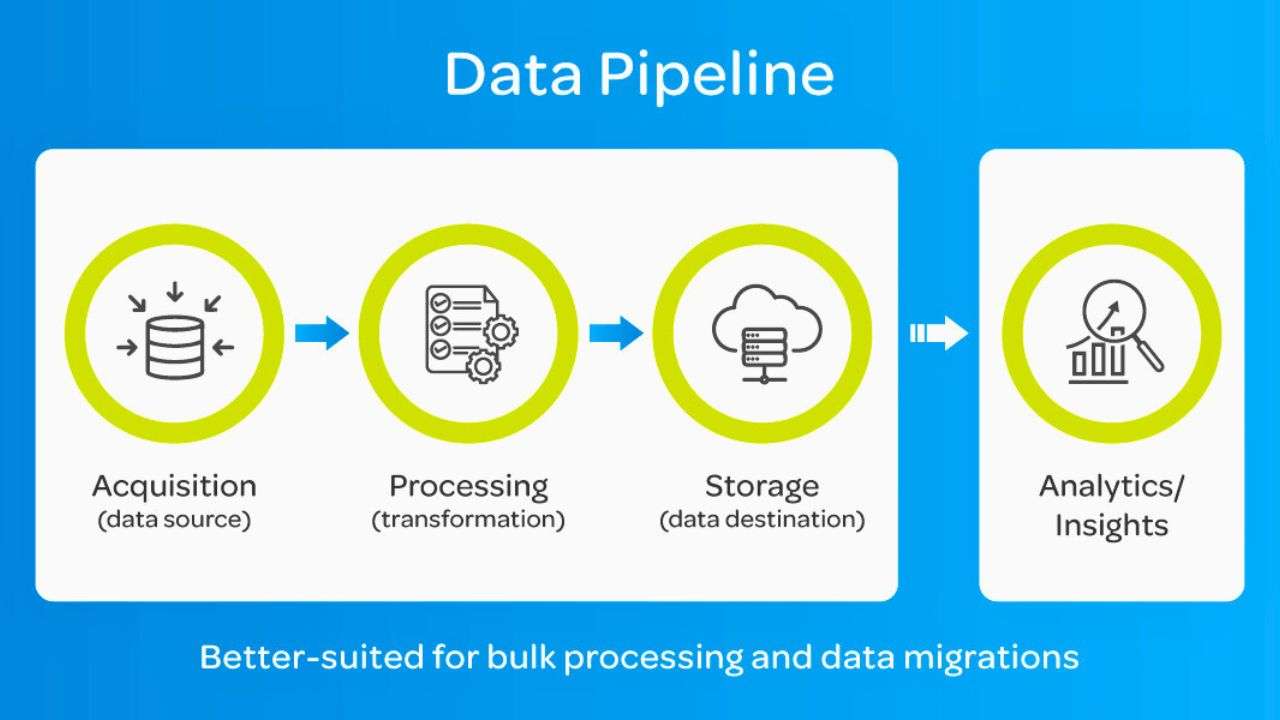
1.1 What is a Data Pipeline?
A data pipeline encompasses the end-to-end process of moving data from one system to another. This includes copying, transferring, and potentially combining data across various systems.
- Key Features:
- Supports both batch processing and real-time streaming.
- Transfers data without mandating transformation.
- Can include ETL processes as a subset.
- Purpose:
- To ensure seamless, consistent data flow across systems for analytics or operational tasks.
1.2 What is an ETL Pipeline?
An ETL pipeline focuses on three sequential processes: extraction, transformation, and loading. It emphasizes preparing data for analysis by transforming it into a usable format.
- Key Features:
- Involves extensive data cleaning and transformation.
- Targets structured or semi-structured data.
- Often integrates with data warehouses or databases.
- Purpose:
- To prepare data for specific analytical tasks or reporting.
2. ETL Pipeline: A Closer Look
2.1 Components of an ETL Pipeline
- Extraction:
- Collects data from diverse sources such as business applications, IoT sensors, or cloud platforms.
- Transformation:
- Converts raw data into a standardized format. This step may include:
- Data cleaning (removing inconsistencies).
- Aggregation (e.g., summing monthly sales).
- Normalization (e.g., converting currencies).
- Converts raw data into a standardized format. This step may include:
- Loading:
- Saves the transformed data into target systems like data warehouses.
2.2 Use Cases of ETL Pipelines
- Centralized Data Integration:
- Example: Consolidating customer information from CRM systems for unified dashboards.
- Historical Data Analysis:
- Useful for analyzing trends by aggregating past transactional data.
2.3 Benefits of ETL Pipelines
- Efficient Decision-Making:
- Readily available, transformed data speeds up analysis.
- Scalability:
- Handles growing data volumes without performance loss.
- Improved Data Accessibility:
- Centralizes data, eliminating manual data aggregation efforts.
3. Data Pipeline: A Comprehensive Insight
3.1 Characteristics of a Data Pipeline
- Broader Scope:
- Can move untransformed data between systems.
- Versatile Operations:
- Includes tasks like real-time data streaming, batch processing, and cloud integration.
- Flexible Destinations:
- Data may end up in data lakes, cloud storage, or even trigger downstream processes like API calls.
3.2 Use Cases of Data Pipelines
- Real-Time Analytics:
- Example: Monitoring social media trends as they unfold.
- Predictive Modeling:
- Example: Production forecasting to avoid supply chain bottlenecks.
3.3 Benefits of Data Pipelines
- Agility in Processing:
- Ideal for applications requiring immediate insights.
- Diverse Integrations:
- Connects seamlessly with modern cloud ecosystems and tools like Apache Kafka or Spark.
- Consistent Data Access:
- Ensures uninterrupted data availability across systems.
4. Key Differences Between Data Pipelines and ETL Pipelines
| Aspect | Data Pipeline | ETL Pipeline |
|---|---|---|
| Purpose | Transfers data; may include transformations. | Extracts, transforms, and loads data for analysis. |
| Scope | Broader; encompasses ETL and non-ETL tasks. | Narrower; focused on transforming data. |
| Processing | Real-time or batch. | Primarily batch-oriented. |
| Flexibility | Adapts to unstructured and real-time data. | Best suited for structured or semi-structured data. |
| Complexity | Less transformation; simpler setup. | Requires significant design effort upfront. |
| Tools | Apache Kafka, AWS pipelines, etc. | Informatica, Talend, etc. |
5. Choosing Between a Data Pipeline and ETL Pipeline
When deciding between a data pipeline and an ETL pipeline, it is essential to assess your business needs, data requirements, and integration goals. Let’s break this down into actionable considerations and scenarios:
Use Case-Based Decision Making
- Batch vs. Real-Time Requirements
- ETL Pipeline: Ideal for batch processing where data does not require immediate updates. For instance, historical sales data analysis or monthly reporting systems.
- Data Pipeline: Perfect for real-time processing, such as monitoring customer interactions in e-commerce platforms or analyzing streaming IoT sensor data.
- Complex Transformations vs. Simple Data Flow
- ETL Pipeline: Better suited for scenarios where data undergoes complex transformations. For example, converting raw data from disparate sources into a normalized format for a centralized data warehouse.
- Data Pipeline: Optimal when the focus is on seamless data transfer with minimal transformations, such as replicating logs from application servers into cloud storage.
- Data Volume and Variety
- ETL Pipeline: Handles structured and semi-structured data effectively, particularly when consolidating data from multiple diverse sources.
- Data Pipeline: Excels in handling unstructured data and vast, continuous data streams, such as social media feeds or log data.
Flexibility and Scalability
- Scalability Needs
- Data pipelines often integrate with big data technologies like Apache Kafka and Apache Spark, enabling seamless scalability for high-velocity data streams.
- ETL pipelines are more traditional, scaling effectively within structured environments but potentially requiring significant overhead when adapting to unstructured data.
- Tooling and Ecosystem
- Choose ETL pipelines if your organization relies on legacy systems and pre-established workflows tied to traditional data warehouses.
- Opt for data pipelines for modern architectures leveraging cloud platforms, distributed systems, and big data ecosystems.
Hybrid Approaches
In many cases, organizations benefit from combining both pipelines:
- ETL for batch updates: Use ETL pipelines for periodic, complex transformations.
- Data pipelines for agility: Use real-time data pipelines for continuous updates and streaming analytics.
6. Real-World Scenarios
Scenario 1: Retail Business Analytics
A large retail chain gathers data from multiple sources, including:
- Point of Sale (POS) systems
- E-commerce platforms
- Social media interactions
Use Case:
The retail chain wants to:
- Analyze monthly sales trends.
- Provide real-time personalized recommendations to customers online.
Pipeline Choices:
- ETL Pipeline: Consolidates and transforms historical sales data into a data warehouse for reporting and trend analysis.
- Data Pipeline: Streams real-time customer data to analyze purchase behavior, enabling dynamic recommendations.
Scenario 2: Financial Services Compliance
A financial institution processes transactions across millions of accounts daily and must adhere to strict regulatory compliance.
Use Case:
The institution needs to:
- Detect fraudulent transactions in real-time.
- Archive monthly transaction data for regulatory audits.
Pipeline Choices:
- ETL Pipeline: Batches transaction data, transforms it, and loads it into secure storage for audit purposes.
- Data Pipeline: Streams real-time transaction data through anomaly detection systems to flag potential fraud.
Scenario 3: IoT Data Monitoring
A manufacturing company monitors equipment health using IoT sensors.
Use Case:
The company aims to:
- Predict equipment failures before they occur.
- Generate daily operational reports.
Pipeline Choices:
- Data Pipeline: Streams sensor data continuously to predictive maintenance systems for real-time monitoring.
- ETL Pipeline: Processes daily sensor readings to generate batch reports on equipment efficiency and utilization.
Scenario 4: Media and Entertainment Streaming
A video streaming service collects user interaction data to improve recommendations and optimize content delivery.
Use Case:
The service wants to:
- Provide personalized recommendations based on user behavior.
- Analyze content performance over time.
Pipeline Choices:
- Data Pipeline: Streams user interactions in real time to recommendation engines, enabling dynamic updates to content suggestions.
- ETL Pipeline: Processes historical viewership data, generating insights on long-term trends for content acquisition strategies.
Scenario 5: Healthcare Data Integration
A hospital network integrates patient data from various departments, including:
- Electronic Health Records (EHRs)
- Lab systems
- Wearable devices
Use Case:
The hospital needs to:
- Centralize patient data for comprehensive health records.
- Monitor real-time vital signs for critical patients.
Pipeline Choices:
- ETL Pipeline: Integrates and transforms patient records from different systems into a single database.
- Data Pipeline: Streams real-time data from wearables to alert medical staff of critical changes.
Scenario 6: Marketing Campaign Management
A global marketing agency manages campaigns across diverse platforms, including email, social media, and digital ads.
Use Case:
The agency aims to:
- Evaluate past campaign performance to guide strategy.
- Adjust live campaigns based on current engagement metrics.
Pipeline Choices:
- ETL Pipeline: Transforms and consolidates historical campaign data for performance reports.
- Data Pipeline: Streams real-time engagement data to dynamically adjust ad placements and content.
7. Data Pipeline vs. ETL Pipeline: Key Takeaways
- Both ETL and data pipelines are essential for modern data strategies.
- They complement rather than replace each other in many setups.
- ETL Pipelines: Focus on data preparation for detailed analytics.
- Data Pipelines: Enable real-time decision-making and broad data transfers.
- Businesses often use both in tandem to maximize data utility.
8. Conclusion
Whether you prioritize the transformation and structuring capabilities of ETL pipelines or the real-time versatility of data pipelines depends on your specific business needs. With the evolution of technology, integrating these pipelines strategically can unlock unparalleled insights, efficiency, and scalability for any organization.
Read Also: