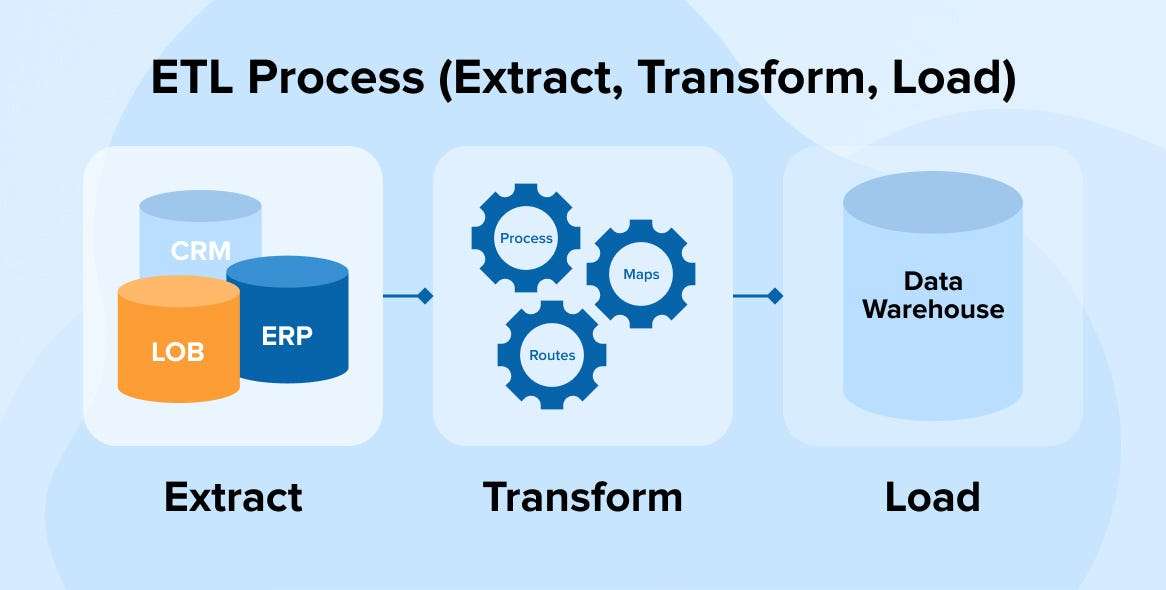
Python, renowned for its flexibility, simplicity, and extensive library ecosystem, is a favored language for building ETL (Extract, Transform, Load) pipelines. These pipelines enable data engineers to handle large-scale data integration tasks efficiently, transforming raw data into structured formats for analysis. Below is an exhaustive guide to building an ETL pipeline in Python, complete with real-world examples.
What is ETL?
ETL is a data integration process comprising three distinct steps:
- Extraction: Collect data from multiple sources such as APIs, databases, or files.
- Transformation: Cleanse, manipulate, and prepare the raw data for analysis.
- Loading: Transfer the transformed data into a destination system like a data warehouse.
Why Use Python for ETL?
Key Advantages
- Extensive Library Ecosystem:
- Libraries like
pandas,NumPy, andSQLAlchemysimplify complex ETL tasks. - Tools like
requestsandBeautiful Soupsupport seamless web scraping and API integration.
- Libraries like
- Integration Flexibility:
- Python integrates with big data tools (e.g., Apache Spark), APIs, and cloud services (e.g., AWS using
boto3).
- Python integrates with big data tools (e.g., Apache Spark), APIs, and cloud services (e.g., AWS using
- Active Community:
- Python’s vast user base ensures access to extensive documentation and community-driven solutions.
- Customizability:
- Python allows for tailored solutions, making it versatile for handling various ETL challenges.
Building an ETL Pipeline with Python
Step 1: Define Data Sources and Destinations
Identify:
- Data sources: APIs, CSV files, or databases.
- Destination systems: Data warehouses (e.g., Snowflake) or cloud storage (e.g., Amazon S3).
Step 2: Plan the Data Flow
Design a data flow diagram to outline:
- Source systems.
- Transformation logic.
- Destination systems.
Step 3: Set Up the Development Environment
- Install Python and libraries:
pip install pandas numpy sqlalchemy pymongo requests - Choose an IDE like PyCharm or Jupyter Notebook for scripting.
Practical Implementation: ETL Pipeline Example
Objective: Transfer data from a CSV file to MongoDB.
Prerequisites
- Python installed.
- MongoDB configured and running.
Code Implementation
1. Import Required Libraries
import pandas as pd
from pymongo import MongoClient
2. Extract Data
Load data from a CSV file:
data = pd.read_csv('sample_data.csv')
print(data.head())
3. Transform Data
- Sort Data:
sorted_data = data.sort_values(by='column_name') - Filter Specific Columns:
filtered_data = data[['column1', 'column2']] - Remove Duplicates:
unique_data = data.drop_duplicates()
4. Load Data
Connect to MongoDB and insert data:
client = MongoClient('mongodb://localhost:27017/')
db = client['etl_demo']
collection = db['processed_data']
# Convert DataFrame to dictionary and insert
data_dict = unique_data.to_dict(orient='records')
collection.insert_many(data_dict)
Key Python Libraries for ETL
1. pandas
- Essential for data manipulation and transformation.
- Example:
cleaned_data = data.dropna() # Remove missing values
2. SQLAlchemy
- Enables smooth database interaction.
- Example:
from sqlalchemy import create_engine engine = create_engine('sqlite:///:memory:') data.to_sql('table_name', engine)
3. requests
- Simplifies API integration.
- Example:
import requests response = requests.get('https://api.example.com/data') api_data = response.json()
4. PyMongo
- Facilitates MongoDB integration.
- Example:
from pymongo import MongoClient client = MongoClient('your_mongo_uri')
Advanced ETL Practices
1. Scheduling ETL Pipelines
Use cron jobs or Python-based schedulers like APScheduler or Apache Airflow for regular pipeline execution.
2. Error Handling and Logging
Ensure smooth debugging with Python’s logging module:
import logging
logging.basicConfig(level=logging.INFO)
try:
# ETL code here
pass
except Exception as e:
logging.error(f"Error: {e}")
3. Handling Large Data Volumes
For memory-intensive tasks, consider:
- Using Chunking:
for chunk in pd.read_csv('large_file.csv', chunksize=1000): process(chunk) - Leveraging Dask: A parallel computing library for processing large datasets.
Python ETL Use Cases
1. Finance
Use Case: Real-Time Financial Analysis
- Problem: Financial institutions need to process vast amounts of data in real-time to monitor trading activity, detect fraud, and comply with regulations.
- Solution: Python-based ETL pipelines can be employed to extract data from stock exchanges, transform it to identify anomalies or trends, and load it into analytics systems.
- Libraries: Use
confluent-kafka-pythonfor streaming,pandasfor data manipulation, andscikit-learnfor predictive analysis. - Example: Extract real-time stock prices, clean and structure the data, and use a machine learning model to forecast market trends.
2. Social Media Analytics
Use Case: Sentiment Analysis for Brand Reputation
- Problem: Businesses need insights into customer sentiments from massive amounts of unstructured social media data.
- Solution: ETL pipelines built with Python can extract tweets, perform natural language processing (NLP) for sentiment analysis, and load results into dashboards for decision-making.
- Libraries: Use
Tweepyfor Twitter API integration,TextBloborNLTKfor NLP, andmatplotliborseabornfor visualizations. - Example: Extract tweets mentioning your brand, clean and tokenize text, perform sentiment analysis, and load insights into a data warehouse.
3. E-Commerce
Use Case: Customer Personalization
- Problem: E-commerce platforms need personalized product recommendations for enhancing user experience.
- Solution: Python ETL pipelines can integrate customer data from purchase history, browsing behavior, and feedback forms to deliver tailored marketing campaigns.
- Libraries: Use
pandasfor data merging and cleaning,NumPyfor mathematical operations, andscikit-learnfor recommendation engines. - Example: Combine customer browsing and purchase data to recommend similar or complementary products.
4. Healthcare
Use Case: Patient Data Integration
- Problem: Healthcare providers need a unified view of patient data from disparate systems to improve care delivery.
- Solution: Python ETL pipelines can integrate electronic health records (EHRs) from multiple sources, clean and structure the data, and store it in a centralized data lake for analysis.
- Libraries: Use
pymongofor MongoDB integration,pandasfor data manipulation, andFHIRlibraries for handling healthcare-specific data formats. - Example: Consolidate patient histories from various clinics to provide personalized treatment recommendations.
5. IoT and Smart Devices
Use Case: Predictive Maintenance
- Problem: IoT devices generate large volumes of real-time data that need to be analyzed for predictive maintenance.
- Solution: Python ETL pipelines can process and analyze this data to detect patterns that indicate potential device failures.
- Libraries: Use
PySparkfor handling big data,NumPyfor statistical calculations, andKafka-pythonfor streaming data from IoT devices. - Example: Analyze IoT sensor data to predict and prevent machine failures.
Challenges in Python ETL
1. Performance Issues
- Problem: Python’s interpreted nature can result in slower execution compared to compiled languages, making it challenging for large-scale ETL processes.
- Solution: Optimize transformations using vectorized operations with
NumPyor implement parallel processing withmultiprocessingorDask.
2. Memory Consumption
- Problem: Libraries like
pandascan consume significant memory, especially with large datasets, potentially leading to crashes. - Solution: Use chunking methods in
pandasor opt for distributed frameworks likePySpark.
3. Scalability
- Problem: As data volumes grow, Python’s limitations in threading (due to the Global Interpreter Lock, or GIL) can hinder scalability.
- Solution: Leverage big data tools like
Apache Spark(via PySpark) or use cloud-based ETL services.
4. Error Handling
- Problem: ETL pipelines often involve diverse data formats and sources, which can result in unpredictable errors.
- Solution: Implement robust logging mechanisms with Python’s
logginglibrary and design custom exception handling.
5. Data Type Mismatches
- Problem: Disparate data sources may use inconsistent data types, leading to errors during transformations or loading.
- Solution: Use libraries like
SQLAlchemyfor handling database schemas and ensure type conversions during transformations.
6. Maintenance Complexity
- Problem: Manually maintaining Python scripts for complex ETL workflows becomes cumbersome.
- Solution: Use workflow orchestration tools like
Apache AirfloworLuigito manage dependencies and schedule tasks.
7. Expertise Barrier
- Problem: Building and maintaining Python ETL pipelines require technical expertise.
- Solution: Use simplified ETL tools or pre-built connectors to lower the technical barrier.
Tools to Simplify Python ETL
1. Apache Airflow
- Description: An open-source platform for orchestrating complex workflows.
- Key Features:
- Task scheduling and monitoring.
- Extensible Python operators for ETL tasks.
- Use Case: Automating the entire ETL process with a visualized DAG (Directed Acyclic Graph).
2. PyAirbyte
- Description: A Python library by Airbyte that offers pre-built connectors for data extraction.
- Key Features:
- Pre-configured connectors for popular data sources and destinations.
- Supports incremental data updates.
- Use Case: Simplifying the integration of APIs and databases into your ETL pipeline.
3. Pandas
- Description: A Python library for data manipulation and transformation.
- Key Features:
- Powerful DataFrame operations.
- Integration with other libraries like
SQLAlchemyandmatplotlib.
- Use Case: Cleaning and transforming small-to-medium-sized datasets.
4. PySpark
- Description: A Python API for Apache Spark for big data processing.
- Key Features:
- Distributed processing for scalability.
- Support for real-time streaming and machine learning.
- Use Case: Processing large-scale datasets that exceed the capacity of
pandas.
5. Luigi
- Description: A Python package for building long-running pipelines.
- Key Features:
- Task dependency management.
- Visualization of workflows.
- Use Case: Maintaining modular and reproducible ETL workflows.
6. SQLAlchemy
- Description: A toolkit for SQL and object-relational mapping (ORM).
- Key Features:
- Seamless interaction with relational databases.
- Simplifies database connectivity.
- Use Case: ETL processes that involve heavy database interactions.
7. Dask
- Description: A Python library for parallel computing.
- Key Features:
- Scalable pandas-like operations on large datasets.
- Integration with machine learning libraries.
- Use Case: Handling large datasets without switching to a full big data framework.
8. Beautiful Soup
- Description: A library for web scraping and data extraction.
- Key Features:
- Parsing HTML/XML documents.
- Searching and modifying parsed content.
- Use Case: Extracting data from web sources like product reviews or social media.
9. Prefect
- Description: A workflow orchestration tool for data automation.
- Key Features:
- Dynamic task scheduling.
- Error notifications and retries.
- Use Case: Monitoring and automating data pipelines with built-in dashboards.
10. AWS Glue
- Description: A managed ETL service by Amazon.
- Key Features:
- Serverless execution.
- Integration with AWS services like S3 and Redshift.
- Use Case: Building Python-based ETL pipelines in a cloud-native environment.
Common Python Libraries for ETL
Python offers a robust ecosystem of libraries tailored for different stages of ETL (Extract, Transform, Load) processes. Here’s a categorized list:
1. Libraries for Data Extraction
- SQLAlchemy
- Purpose: Database interaction.
- Features:
- Connects to relational databases (e.g., MySQL, PostgreSQL, SQLite).
- Supports Object-Relational Mapping (ORM) for structured querying.
- Use Case: Extract data from SQL databases.
- PyMongo
- Purpose: MongoDB interaction.
- Features:
- Efficiently extracts data from MongoDB collections.
- Supports CRUD operations.
- Use Case: Extract unstructured data from NoSQL databases.
- Tweepy
- Purpose: Twitter API integration.
- Features:
- Extracts tweets in real-time.
- Stream API for live data.
- Use Case: Social media analytics and sentiment analysis.
- Requests
- Purpose: HTTP requests handling.
- Features:
- Makes API calls to RESTful services.
- Supports headers, parameters, and authentication.
- Use Case: Extract data from REST APIs.
- Beautiful Soup
- Purpose: Web scraping.
- Features:
- Parses HTML/XML documents.
- Extracts specific data elements from web pages.
- Use Case: Extract data from websites.
- pysftp
- Purpose: File transfer via SFTP.
- Features:
- Extract files securely from remote servers.
- Supports private/public key authentication.
- Use Case: Fetch data files from secure servers.
2. Libraries for Data Transformation
- Pandas
- Purpose: Data manipulation and analysis.
- Features:
- DataFrame structure for handling tabular data.
- Supports operations like merging, grouping, and filtering.
- Use Case: Clean and transform structured datasets.
- NumPy
- Purpose: Numerical computations.
- Features:
- Handles large multidimensional arrays and matrices.
- Performs mathematical transformations efficiently.
- Use Case: Transform numerical datasets.
- Dask
- Purpose: Parallel computing for large datasets.
- Features:
- Processes data larger than memory.
- Provides a pandas-like interface.
- Use Case: Transform large datasets in parallel.
- PySpark
- Purpose: Big data processing.
- Features:
- Distributed data transformations.
- Real-time data processing with Spark Streaming.
- Use Case: Handle large-scale data transformations.
- Regular Expressions (re)
- Purpose: Text pattern matching.
- Features:
- Extract, clean, or replace text patterns.
- Use Case: Standardize data formats like dates or phone numbers.
- NLP Libraries (NLTK, spaCy, TextBlob)
- Purpose: Text analysis.
- Features:
- Tokenization, stemming, lemmatization.
- Sentiment analysis.
- Use Case: Transform textual data for analysis.
3. Libraries for Data Loading
- SQLAlchemy
- Purpose: Load data into relational databases.
- Features:
- Batch data insertion.
- Supports multiple database engines.
- Use Case: Load transformed data into SQL databases.
- Boto3
- Purpose: AWS services interaction.
- Features:
- Upload files to AWS S3 or DynamoDB.
- Use Case: Load data into cloud storage or data lakes.
- pyodbc
- Purpose: Connect to ODBC-compliant databases.
- Features:
- Supports various databases like SQL Server and Oracle.
- Use Case: Load data into enterprise databases.
- FSSpec
- Purpose: Unified file system interface.
- Features:
- Handles local, cloud, and remote file systems.
- Use Case: Load data into diverse storage systems.
- Google Cloud Client Libraries
- Purpose: Google Cloud integration.
- Features:
- Upload data to Google BigQuery or Google Cloud Storage.
- Use Case: Store data in Google Cloud services.
- fastavro
- Purpose: Handle Avro files.
- Features:
- Fast serialization and deserialization of Avro data.
- Use Case: Load Avro-formatted data into analytics systems.
- pandas.to_csv() / pandas.to_sql()
- Purpose: Simplified data loading.
- Features:
- Writes data directly to CSV, Excel, or SQL databases.
- Use Case: Quickly load data in small projects.
4. Libraries for Workflow Orchestration
- Apache Airflow
- Purpose: Manage ETL workflows.
- Features:
- Visual DAG representation.
- Monitors and schedules tasks.
- Use Case: Automate complex ETL pipelines.
- Luigi
- Purpose: Pipeline management.
- Features:
- Task dependency handling.
- Built-in logging.
- Use Case: Modular ETL task execution.
- Prefect
- Purpose: Orchestration and monitoring.
- Features:
- Dynamic task scheduling.
- Cloud-based monitoring options.
- Use Case: Orchestrate modern ETL pipelines with minimal setup.
Conclusion
Building an ETL pipeline with Python combines the flexibility of coding with powerful data processing capabilities. While it comes with challenges, tools like PyAirbyte and libraries such as pandas and SQLAlchemy make Python a reliable choice for ETL tasks. With proper planning, error handling, and optimization techniques, Python ETL pipelines can handle everything from small-scale projects to enterprise-grade applications.