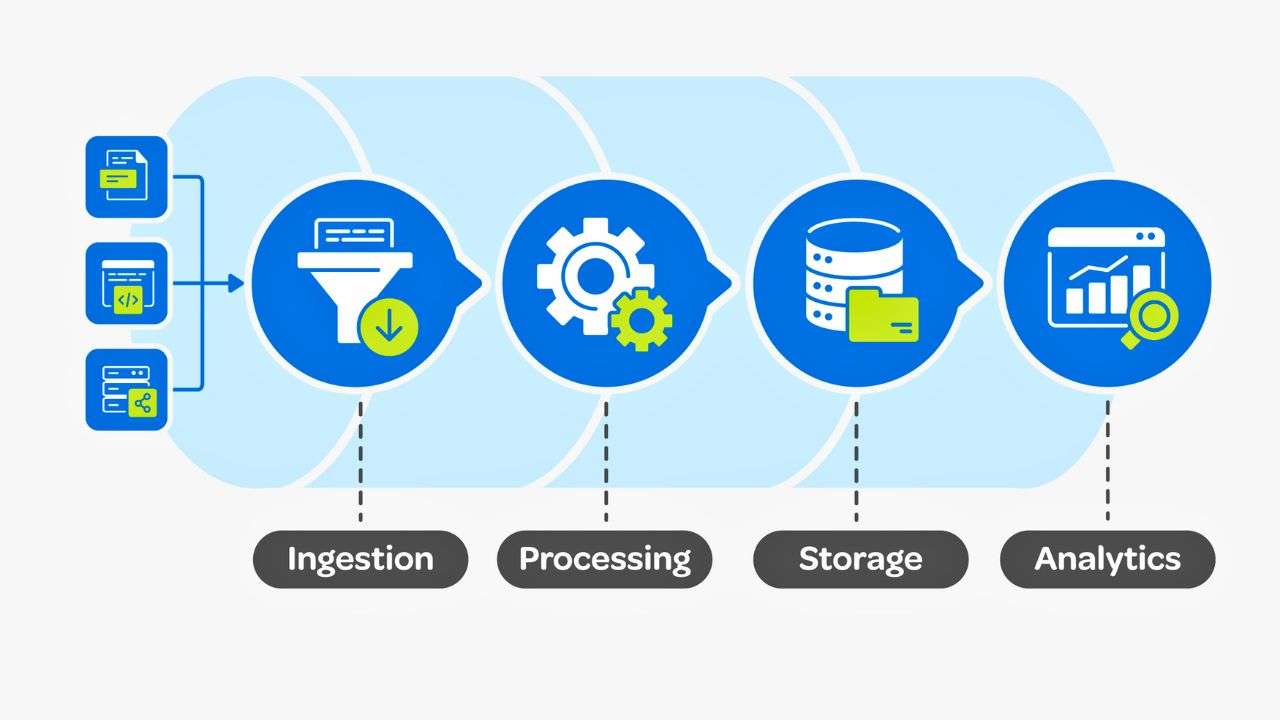
Data is the cornerstone of modern business strategies, influencing everything from decision-making to product development. For 94% of enterprises, data drives digital initiatives and business growth. Yet, many organizations struggle to unlock the full potential of their data due to its scattered nature.
A data pipeline is a structured process that moves data from disparate sources to a unified destination, enabling efficient analysis and decision-making. Constructing such a pipeline can be time-consuming, ranging from weeks to months depending on complexity. This guide outlines how to build a data pipeline effectively and provides actionable insights for success.
What is a Data Pipeline?
A data pipeline is a series of processes designed to automate the collection, transformation, storage, and analysis of data. It acts as the backbone for various applications such as real-time analytics, machine learning, and business intelligence.
Steps to Build a Robust Data Pipeline
Step 1: Define Your Goals
- Clearly outline your objectives to guide the pipeline’s design and scope. Examples include:
- Enabling real-time analytics for faster decision-making.
- Supporting machine learning models with clean, structured data.
- Synchronizing data across multiple systems.
- Key considerations:
- Data volume and frequency of updates.
- Desired speed of processing and analysis.
Step 2: Identify Data Sources
- Pinpoint your data sources, categorized as:
- Databases: MySQL, PostgreSQL, MongoDB, or Cassandra.
- Cloud Storage: AWS S3, Google Cloud Storage, or Azure Blob Storage.
- Real-time Data Streams: IoT devices, social media feeds, or server logs.
- File Sources: CSV, Excel, JSON, or XML formats.
- APIs: Connections to external platforms like Salesforce or HubSpot.
- Understand the format, volume, and quality of these sources, as they influence data ingestion and transformation strategies.
Step 3: Determine the Data Ingestion Strategy
- Choose an appropriate ingestion method:
- Batch Ingestion:
- Processes data at scheduled intervals.
- Suitable for large volumes of static data.
- Example: Nightly aggregation of sales data.
- Real-time Ingestion:
- Processes data immediately as it is generated.
- Ideal for time-sensitive applications like fraud detection or stock monitoring.
- Batch Ingestion:
Step 4: Design the Data Processing Plan
- Transform raw data into a usable format:
- ETL (Extract, Transform, Load):
- Data is extracted, transformed on a staging server, and then loaded.
- Suitable for smaller datasets and scenarios where data reuse is common.
- ELT (Extract, Load, Transform):
- Data is extracted and loaded into the destination, then transformed.
- Ideal for handling large datasets in big data environments.
- ETL (Extract, Transform, Load):
- Include:
- Data cleaning (removing duplicates, correcting errors).
- Validation (ensuring data integrity).
- Formatting (standardizing units, time zones).
Step 5: Decide Where to Store the Information
- Select a storage solution based on your needs:
- Data Warehouses: For structured data, e.g., Amazon Redshift.
- Data Lakes: For unstructured/semi-structured data, e.g., Google Cloud Storage.
- Databases: For transactional data, e.g., PostgreSQL.
- Consider scalability, security, and integration capabilities.
Step 6: Establish the Workflow
- Define a logical sequence for data operations:
- Task dependencies and execution order.
- Error handling procedures and recovery strategies.
- Retries and notifications for failures.
- Example tools: Apache Airflow or AWS Step Functions.
Step 7: Set a Monitoring Framework
- Implement monitoring for:
- Tracking data flow through the pipeline.
- Identifying errors or bottlenecks.
- Analyzing resource usage and performance metrics.
- Regular monitoring ensures early detection of issues, minimizing downtime.
Step 8: Implement the Data Consumption Layer
- Create user-friendly access to processed data:
- BI Tools: Tableau or Power BI for data visualization.
- Reporting Tools: Automated report generation.
- APIs: Enable integration with applications.
- Ensure interfaces are intuitive and responsive to user needs.
Best Practices for Building Data Pipelines
Building a robust data pipeline requires not only technical expertise but also adherence to best practices to ensure scalability, security, and efficiency. Below are detailed best practices to streamline the process:
1. Streamline Development and Deployment
- Adopt CI/CD Pipelines:
- Continuous Integration (CI): Automatically test and integrate new code changes to identify issues early.
- Continuous Deployment (CD): Deploy tested changes seamlessly to production environments.
- Tools: Jenkins, GitLab CI/CD, CircleCI.
- Benefits:
- Faster development cycles.
- Reduced manual intervention and human errors.
- Simplified rollback mechanisms in case of issues.
2. Maintain Consistency with Version Control
- Use version control systems like Git to:
- Manage code changes collaboratively.
- Track modifications for better accountability.
- Roll back to stable versions in case of errors.
- Enforce coding standards and peer reviews to maintain quality.
3. Optimize Data Management
- Data Partitioning:
- Break large datasets into smaller, manageable parts based on criteria like time (daily, monthly) or categories (regions, departments).
- Benefits:
- Improved query performance.
- Reduced processing time.
- Data Compression:
- Store data in compressed formats like Parquet or Avro to reduce storage costs and improve performance.
- Schema Evolution:
- Plan for schema changes to ensure compatibility when data sources evolve.
4. Leverage Modern Architectures
- Containers:
- Use Docker or Kubernetes for containerization.
- Benefits:
- Consistent environments across development and production.
- Simplified scaling and deployment.
- Microservices:
- Break the pipeline into independent services that communicate via APIs.
- Benefits:
- Easier debugging and maintenance.
- Scalability to handle increased workloads.
5. Ensure Data Security
- Encryption:
- Encrypt data at rest and in transit to protect sensitive information.
- Access Controls:
- Implement role-based access to limit data access to authorized users only.
- Compliance:
- Adhere to industry regulations such as GDPR, HIPAA, or CCPA, especially when handling personal or financial data.
- Regular Audits:
- Periodically review the pipeline for vulnerabilities and address them proactively.
6. Monitor and Optimize Performance
- Resource Monitoring:
- Use tools like Prometheus or Datadog to monitor CPU, memory, and I/O usage.
- Bottleneck Analysis:
- Identify slow stages in the pipeline and optimize them.
- Example: Parallelize data processing tasks to reduce latency.
- Alerting Systems:
- Set up real-time alerts for failures or anomalies using tools like PagerDuty.
Manual vs. Automated Data Pipelines
Manual Data Pipelines
- Characteristics:
- Built using custom code, typically in Python, Java, or shell scripts.
- Tailored to specific use cases but require significant effort to maintain.
- Pros:
- Complete control over the pipeline design and implementation.
- Flexibility to integrate with unconventional data sources.
- Cons:
- Time-intensive development process.
- Error-prone, especially with large or complex pipelines.
- Scalability challenges due to lack of built-in automation.
- Limited monitoring and error-handling capabilities.
Automated Data Pipelines
- Characteristics:
- Built using dedicated tools like Astera, Talend, Apache NiFi, or Informatica.
- Incorporate prebuilt connectors, automation features, and monitoring capabilities.
- Pros:
- Rapid development and deployment with minimal coding.
- Built-in scalability for handling large datasets or increased data sources.
- Comprehensive monitoring and error-handling mechanisms.
- Easier to manage compliance and data governance requirements.
- Cons:
- Dependency on third-party tools.
- Higher upfront costs compared to manual pipelines.
Key Decision Factors:
| Aspect | Manual Pipelines | Automated Pipelines |
|---|---|---|
| Development Time | High | Low |
| Error Rate | Higher (manual coding errors) | Lower (automated validation) |
| Cost | Low upfront, high maintenance | High upfront, low maintenance |
| Scalability | Limited | High |
| Monitoring | Requires custom solutions | Built-in with real-time tracking |
Case Study: Building Data Pipelines with Astera
Astera simplifies the pipeline-building process with its powerful, user-friendly features, enabling businesses to streamline data management. Below is an example workflow using Astera:
1. Data Extraction
- Extract data seamlessly from multiple sources:
- Supported Sources: SQL databases, flat files (CSV, JSON, XML), cloud platforms (Salesforce, AWS).
- Example: Extracting customer data from an Oracle database and sales data from CSV files.
- Key Features:
- Prebuilt connectors for faster integration.
- Support for batch and real-time data ingestion.
2. Data Transformation
- Clean, validate, and structure the data:
- Example Transformations:
- Removing duplicate customer records.
- Aggregating sales data by region.
- Converting date formats for consistency.
- Example Transformations:
- Key Features:
- Drag-and-drop transformation tools for ease of use.
- Support for complex transformations like joins, lookups, and conditional mappings.
3. Data Loading
- Load processed data into target systems:
- Key Features:
- Automated load balancing to optimize resource usage.
- Support for incremental and full data loads.
4. Automation and Scheduling
- Set up automated workflows:
- Example: Schedule daily pipeline runs at 2 AM to process sales data from the previous day.
- Key Features:
- Time-based scheduling or event-triggered automation.
- Notifications for successful or failed runs.
5. Monitoring and Error Handling
- Real-time monitoring ensures smooth pipeline operation:
- Example: Detecting delays in data ingestion and retrying automatically.
- Key Features:
- Dashboard for tracking pipeline performance.
- Automatic error logging and retry mechanisms.
Benefits of Using Astera:
- Efficiency: Reduces development time significantly compared to manual pipelines.
- Scalability: Handles large data volumes with ease.
- Ease of Use: Intuitive interface eliminates the need for extensive coding.
- Security: Built-in compliance with data privacy regulations.
Conclusion
Building a data pipeline involves meticulous planning, the right tools, and adherence to best practices. Whether starting with a simple pipeline or developing a complex, automated system, following these steps ensures a robust framework for data management. By leveraging tools like Astera, you can significantly reduce the time and effort required, focusing more on deriving actionable insights from your data.